
【LeetCode】79. Word Search 解題報告
79. Word Search / Medium
Given an m x n grid of characters board and a string word, return true if word exists in the grid.
The word can be constructed from letters of sequentially adjacent cells, where adjacent cells are horizontally or vertically neighboring. The same letter cell may not be used more than once.
Example 1:

Input: board = [[“A”,”B”,”C”,”E”],[“S”,”F”,”C”,”S”],[“A”,”D”,”E”,”E”]], word = “ABCCED”
Output: true
Example 2:
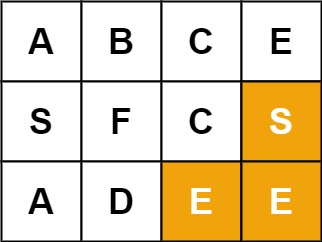
Input: board = [[“A”,”B”,”C”,”E”],[“S”,”F”,”C”,”S”],[“A”,”D”,”E”,”E”]], word = “SEE”
Output: true
Example 3:

Input: board = [[“A”,”B”,”C”,”E”],[“S”,”F”,”C”,”S”],[“A”,”D”,”E”,”E”]], word = “ABCB”
Output: false
Constraints:
- m == board.length
- n = board[i].length
- 1 <= m, n <= 6
- 1 <= word.length <= 15
- board and word consists of only lowercase and uppercase English letters.
- Follow up: Could you use search pruning to make your solution faster with a larger board?
Solution 1: Backtracking
思路
很直覺地用 DFS 做 Backtracking。
效能
Complexity
- Time Complexity: O(N*3^L), 3 is the direction every time it takes, where N is the number of cells and L is the length of the word.
- Space Complexity: O(L)
LeetCode Result
- Runtime: 259 ms
- Memory Usage: 8.1 MB
- https://leetcode.com/submissions/detail/731609728/

Code
1 | class Solution { |
Solution 2: Backtracking + Pruning
思路
要加速的話只能做 Pruning(剪枝),也就是在 DFS 的決策樹上,其實我們並不需要搜尋每一個可能,有一些可以決定不搜尋,而決定的過程就叫做 Pruning。
以這題來說有三個 Pruning 的方式:
- 字串 word 長度大於 board 大小。
這種狀況下就沒辦法找到這條路了,可以直接 return false - board 上缺少了 word 中的某個字元。
這種狀況下也沒辦法找到,可以直接 return false - Prefix 與 Suffix 的長度。
設想一種狀況,我們拿到了一個字串是 aaaaaaaaaab,拿到的盤面也很大,並且都是 a,而 b 則是在最右下角。
這種狀態下,若我們按順序 DFS,在初期都會遭遇 aaaaaaaaaaa,所以會花非常多的時間在 DFS 沒有意義的區域。
為了解決這個狀況,我們事先判斷 word 的 prefix 和 suffix 的長度,如果 prefix > suffix,我們就反轉字串。
這樣使得我們可以減少進入 DFS 的可能性。以上面的範例來看,prefix 是 10 而 suffix 是 1,反轉後就會變成 baaaaaaaaaa。
只要做完前兩種 Pruning,就可以把這題的運行時間從 270ms 降到約 75ms,而第三種則直接減至 0ms。
效能
Complexity
- Time Complexity: O(N*3^L), 3 is the direction every time it takes, where N is the number of cells and L is the length of the word.
- Space Complexity: O(L)
LeetCode Result
- Runtime: 0 ms
- Memory Usage: 8 MB
- https://leetcode.com/submissions/detail/740708861/

Code
1 | class Solution { |